
More than working with expert analysts and smarter dashboards, what makes modern data pipelines stand out is working on fresh data that is only a few seconds old. The infrastructure that makes such data available becomes a key differentiator.
However, most B2B enterprises rely on batch data to make real-time decisions, which has become a central problem, undermining their decision-making. The Strategy Team’s report finds that 80% of B2B teams that invest in real time data pipelines report direct revenue growth.
Historical intelligence dresses as a current-time interface, creating a data gap, and real-time data structurally removes this discrepancy.
What Is the Difference Between Batch and Real Time Data Pipelines?
Although many B2B marketers know about their latency problem, none of them is diagnosed correctly. Enterprises often diagnose batch pipelines as extremely slow, but the real diagnosis is that real time data pipeline architecture and batch pipelines structurally solve different problems.
| Parameter | Batch Data Pipelines | Real-time Data Pipelines |
|---|---|---|
| Central Question | Where does data stand at the end of the interval? | What happened, and what action should follow immediately? |
| Design Priority | Full dataset consistency and completeness | Continuity and immediacy of individual events |
| Processing Framework | Scheduled intervals | Continuous |
| Best-fit Use Cases | Regulatory reporting, financial reconciliation, and historical trend analysis | Real-time pricing, operational alerts, fraud detection, and churn interventions |
| Latency | Minutes to hours | Milliseconds to seconds |
| Infrastructural Complexity | Low | High |
| Point of Failure | When stale data is accurately delivered | When real-time data is delivered without the decision owner’s interventions |
Companies that build on batch pipelines to meet real-time requirements fail because their architecture is optimized for a different question. The real difference between the two concepts is the processing philosophy, more than the processing speed.
How Does Real-Time Data Pipeline Architecture for Modern Businesses Work?
Most real-time enterprise data pipeline architectures are built on standard technology stacks, which include Kafka for ingestion, Spark Streaming or Flink for processing, a data warehouse or a time-series database for storage, and a BI layer on top.
The architectural decisions that matter start with the ingestion layer design. When the real time data ingestion layer is built around source systems, the data streaming architecture fails. The processing topology is the second layer, where event driven data pipelines route all events via the same processing path, creating latency and bottlenecks.
At this layer, production-level architectures distinguish high-volume events from high-priority events. The last layer is the schema governance model, which prevents silent failure downstream with better governance.
Resilience and scalability are equally important to speed. Going beyond technological failure, overdependence on designing architectures for data throughput causes the data pipeline frameworks to fail.
How Building Real-Time Data Pipelines for Analytics Drives Decisions?
B2B enterprises, in many cases, build pipelines before specifically deciding what they will support, and this is the most common failure pattern. While engineering teams optimize for throughput, business teams favor actionable outcomes, and this disconnect surfaces after deployment.
Beginning with a specific operational decision, teams reverse track to the data decision needs, followed by calculating tolerable latency, and then devising a format favorable for decision-makers, is how developing real time data pipelines for analytics works.
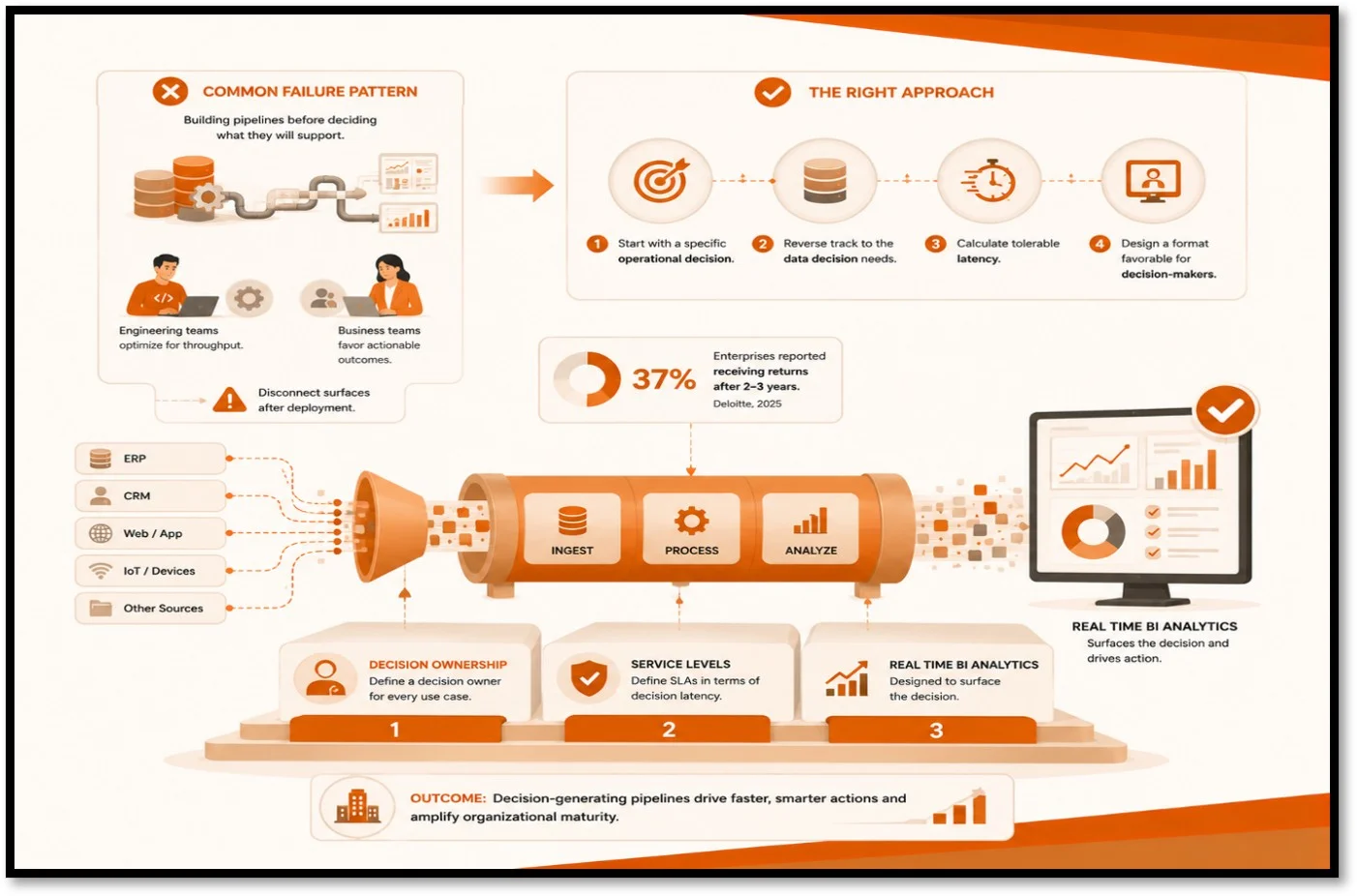
Deloitte’s 2025 research finds that despite rising investments in AI-driven analytics, ROIs have slowed down, and 37% of enterprises reported receiving returns after 2-3 years. This is because B2B teams emphasize technology before operational adoption.
The first thing that distinguishes decision-generating analytics pipelines from dashboard-producing real-time datasets is the defined decision owner for every use case. Service-level arguments form the second layer, where SLAs must be defined in terms of decision latency instead of data latency.
Real time BI analytics is the last layer that is designed to surface the decision. Such an infrastructure amplifies organizational maturity.
How Real Time Data Improves Operational Intelligence?
Real time analytics pipelines are often positioned as a faster BI layer, which is correct in a single use case but incomplete for an enterprise. Organizations are migrating from reporting environments to decision systems, and this shift surfaces where latency structurally changes the outcome.
According to IJCNIS’s 2025 research, businesses that invest in real time decision intelligence experience a 35% increase in decision-making accuracy. The value becomes prominent when the gap between an event and an action is reduced.
In logistics and supply chain, enterprise data engineering architecture surfaces disruptions before they amplify. While a supplier issue surfaced within a few minutes, allowing organizations to find solutions, the same issue spotted after a few hours becomes catastrophic.
Streaming data pipelines for enterprise applications enable fraud detection before the payment settles in the financial services sector. In customer success, on the other hand, analytics platforms intervene before disengagement turns into churn.
Final Thoughts: What Is the Future of Real Time Data Infrastructure for Enterprise Analytics?
Instead of considering real-time data engineering pipelines as a faster version of batch pipelines, one should treat them as a different architectural decision class, which decides if a company can spontaneously act on an event or carry out a post-event analysis. The gap between these two capabilities is competitive.
AI-driven decisioning systems’ dependency on live operational inputs will enable B2B teams with production-grade data architecture to deploy AI at the operational layer. Companies without the layer will continue deploying AI at the reporting layer, which will only compound the discrepancy in the outcome.
Want to know where your data pipeline architecture fails? Book a 30-minute consultation audit with the Knowledgeboats team to find out where your current pipeline architecture introduces decision latency that your company cannot afford.
FAQs
1. How do real time data pipelines work?
Real-time data pipelines continuously ingest, process, and deliver event data, which enables B2B teams to make decisions based on the generated information.
2. Why are real time data pipelines important for businesses?
Real-time data pipelines reduce decision latency. This allows B2B teams to make faster decisions based on operational changes, emerging risks, and buyer behavior.
3. What technologies are used for real time data pipelines?
Kinesis, Flink, Pub/Sub, Kafka, cloud-native event processing platforms, and Spark Streaming are some key technologies that B2B teams use for real-time data pipelines.
4. What are the benefits of real time data pipelines for enterprises?
Operational agility, stronger business responsiveness, faster decisions, improved customer experiences, and fraud prevention are some crucial benefits of real-time data pipelines.
5. How real time data pipelines enable instant business decisions?
These pipelines reduce the latency between events and actions, which helps B2B teams to respond faster, while opportunities become more actionable.



