
B2B enterprises that develop AI models for production often generate the data that they need at scale on demand instead of waiting for real-world information. The gap between training data diversity, which production-grade AI models need, and volume is increasing, creating bottlenecks, and this is the core problem.
Folio3’s analysis finds that 80.3% of AI projects either fail or are delayed due to poor data quality. Synthetic data in enterprise AI bridges this gap by enabling AI development when real data is scarce, dangerously imbalanced, or restricted.
Understanding the concept of synthetic data, at the level where most enterprise decisions break down, is an important prerequisite for evaluating the strategy.
What Is Synthetic Data in AI, and Why B2B Enterprises Use It
Synthetic data replicates the characteristics of real-world datasets to generate artificial information that remains statistically representative without exposing sensitive records. Although it describes outcomes, it overlooks why B2B teams adopt the synthetic data in the first place.
Beyond what most vendor content acknowledges, there are deeper reasons that make synthetic data for AI development fundamental. It bridges the gap between the data enterprises possess and the data they can realistically use to train AI models within legal, operational, and ethical constraints.
For instance, a healthcare enterprise cannot use millions of patient records to train AI models by bypassing HIPAA, IRB approvals, and residual risk management of each downstream model. The entire process requires several months, decelerating AI development.
Synthetic data pipelines bypass this hurdle and create data patterns without accessing the real data. Not only do they retain statistical properties of the real data, but they also help B2B teams maintain data quality by eliminating regulatory and ethical complexities.
Secureframe’s research finds that 70% of B2B teams acknowledged regulatory risk exposure due to proprietary data in AI training. Instead of framing synthetic data as fake data, it should be viewed as engineered training infrastructure.
Privacy-preserving synthetic data ensures AI development occurs at enterprise velocity in regulated industries, and treating it as a shortcut reduces its actual potential.
How Is Synthetic Data Generated for Machine Learning
Most content on synthetic data focuses on GANs, VAEs, agent-based modelling, and diffusion techniques. While technically accurate, this framing overlooks how enterprises generate reliable training data without distorting the patterns models are expected to learn.
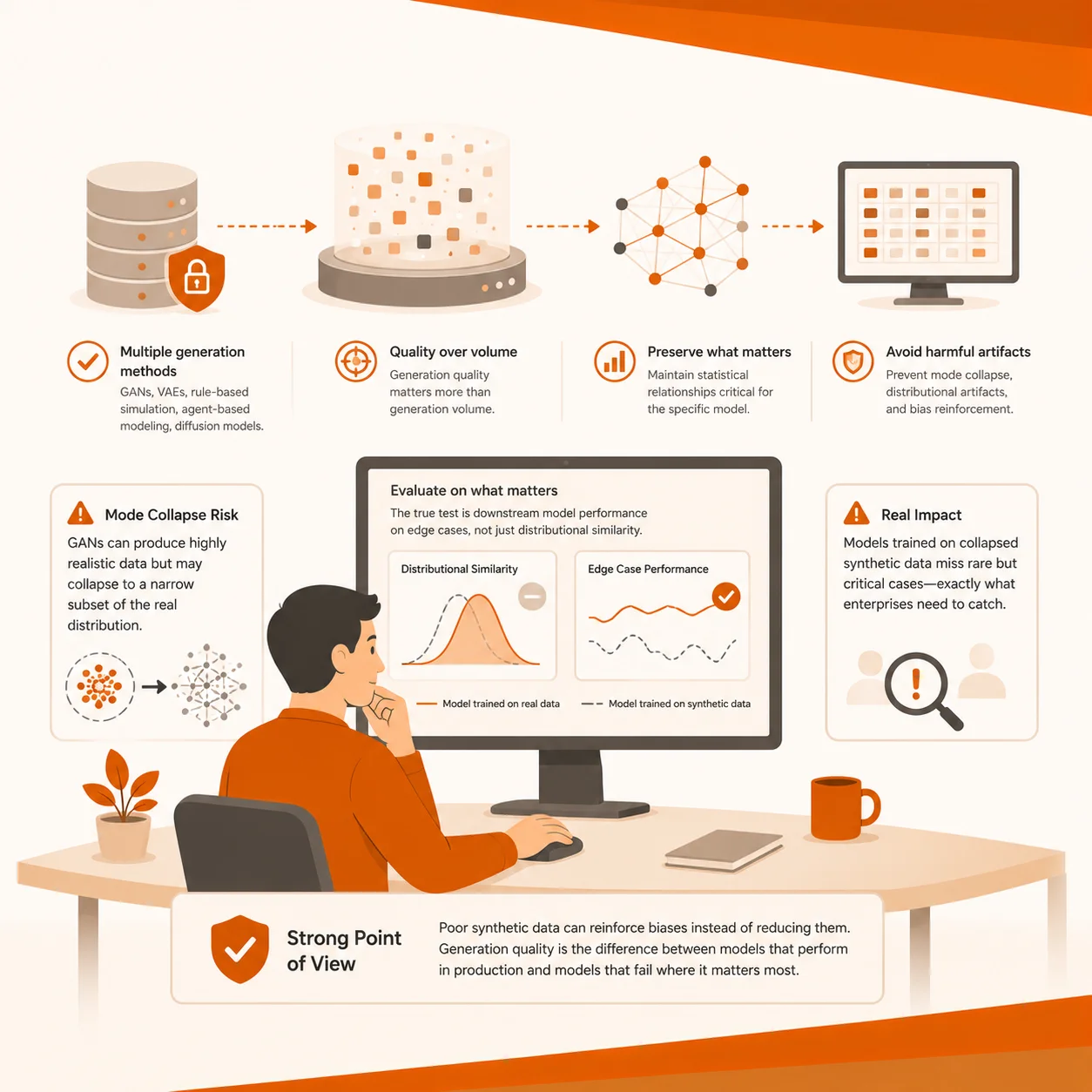
Generative AI for synthetic data using GANs creates hyper-realistic data with mode collapse as a primary failure, where the model captures limited patterns from the original data set instead of showing the entire data range.
Data generation quality is more important than volume, and poor data quality reinforces biases rather than reducing them. The quality of the synthetic data depends on whether AI models trained on this data work seamlessly in conditions that matter most to B2B enterprises.
AI model training datasets often fail in production despite passing quality checks, as they overlook downstream model performance on edge cases and emphasize only distributional similarity.
Where Does Synthetic Data Strategy for AI Development Work
Instead of debating whether synthetic data works, B2B enterprises will find more meaningful conversations about where it works and where collecting and curating real data makes more sense.
Data infrastructure fails when synthetic data is not bound to a clearly defined use case mapping. However, instead of isolated experimentation, synthetic data should be integrated with an enterprise data strategy.
Synthetic data in AI training becomes more reliable in three specific AI use cases:
- Synthetic Data for Computer Vision: It works for logistics and manufacturing industries, where data collection and labeling are costly and time-consuming, allowing teams to generate labeled images and videos for object detection, visual inspection, and defect classification.
- Synthetic Data for LLM Training: Synthetic data is valuable for training autonomous systems, where it can help them create dangerous, hard-to-reproduce, and rare real-world situations for autonomous vehicles, industrial automation systems, and robots.
- Enterprise Machine Learning Data Strategy Augmentation: By creating additional examples of rare events, synthetic data strengthens enterprise ML strategies. It also addresses class imbalance in medical diagnosis, predictive maintenance tools, and fraud detection.
While synthetic data, when treated as a one-size-fits-all solution to data shortages, compounds infrastructural costs, it becomes more valuable when used for clearly defined use cases.
What Are the Benefits of Synthetic Data in Enterprise AI
Most B2B articles hardly ever mention anything beyond scalability, data privacy, and cost reduction as the benefits of synthetic data for enterprise AI models. Although these benefits are valid, they never consider the investments enterprises have to make before scaling those benefits.
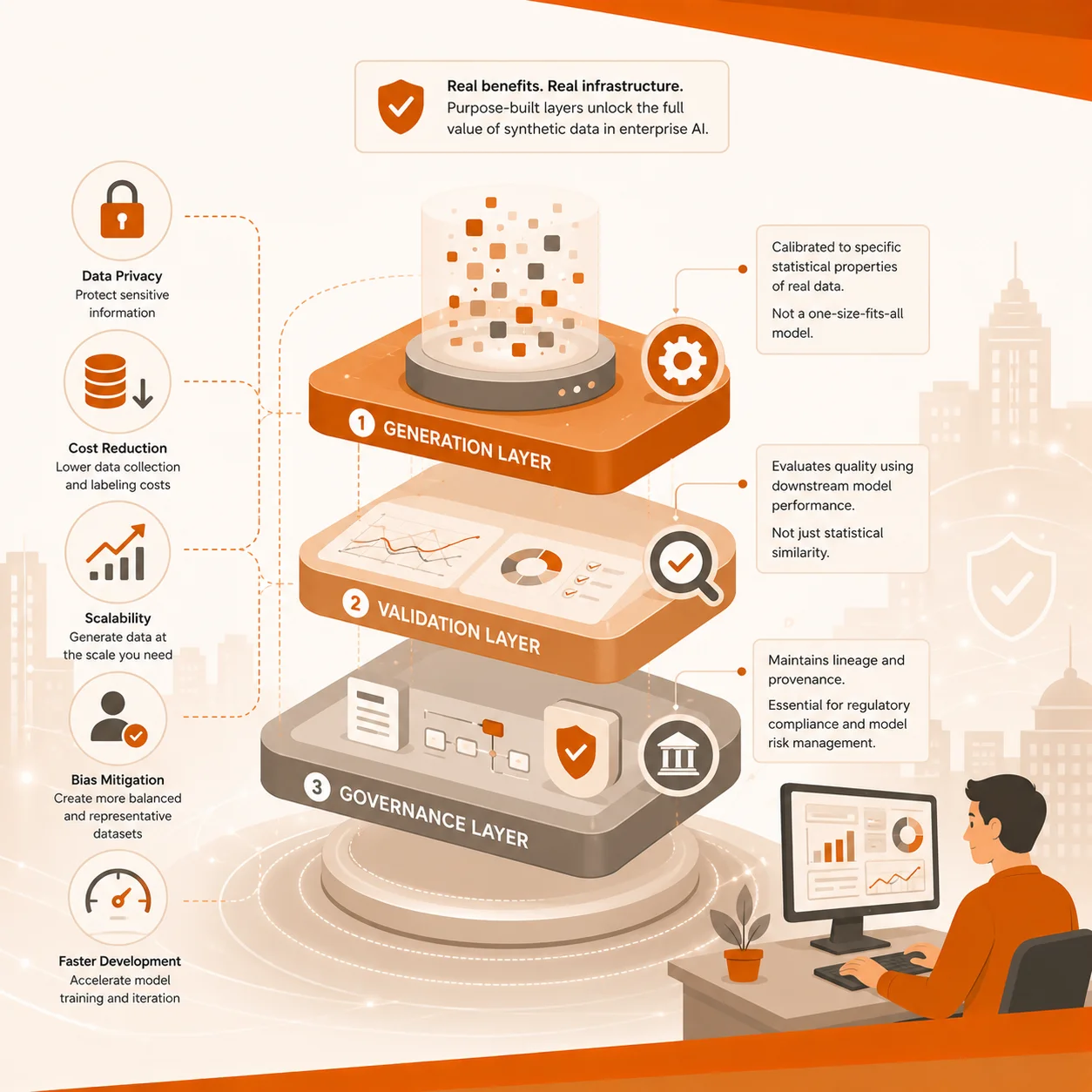
B2B enterprises often underestimate the following three infrastructural layers:
- Generation Layer: It enables synthetic data systems to replicate specific characteristics of real-world datasets relevant to the intended use case. For instance, a model built for clinical trial data cannot be repurposed for financial transactions.
- Validation Layer: Beyond evaluating synthetic data quality against the statistical similarity to source distribution, AI teams can analyze the quality against downstream model performance metrics.
- Governance Layer: It establishes clear lineage between synthetic datasets and their underlying source data while documenting how the data was generated. The healthcare, insurance, and financial services industries emphasize clear documentation to manage AI risks.
Although the value of synthetic data is never under scrutiny, efforts to operationalize it at scale are often underestimated.
Final Thoughts: What is the Future of Synthetic Data in Enterprise Data Strategy
Synthetic data platforms for enterprises are far more than a shortcut to better models. They are strategic infrastructure decisions that govern whether B2B teams can train, test, and validate AI at production speed.
B2B teams treating synthetic data as a tool tailored for use cases will compound their edge in AI development, whereas enterprises treating it as a solution for universal data scarcity will develop costly infrastructure.
However, as global AI regulations tighten, enterprises will be obliged to prove the source of their synthetic data and how it was validated. Rather than being a point of competitive advantage, these practices will become compliance necessities.
Connect with the KnowledgeBoats team to find out if your synthetic data infrastructure caters to production and compliance requirements.
FAQs
1. How is synthetic data generated for machine learning?
Synthetic data for machine learning is generated with the help of diffusion models, GANs, AI techniques replicating real-world data patterns, and simulations.
2. Why are enterprises using synthetic data for AI development?
Synthetic data helps B2B teams bypass privacy restrictions, accelerate AI model development, and reduce costs.
3. How is synthetic data used for generating training datasets using AI?
Synthetic data not only expands limited datasets but also improves model training without revealing any sensitive information and enables the simulation of rare events.
4. How do B2B teams use synthetic data for LLM training?
Using synthetic data, B2B teams can improve LLM performance in specialized applications and expand domain-specific datasets.
5. What are the benefits of synthetic data for AI development?
Reduced data dependency, accelerated AI experimentation, enhanced privacy, and scalability support are core benefits of synthetic data.



